-
SWAT4HCLS 2026
A bit over a week ago, SWAT4HCLS 2026 took place, with the matching biohackathon on Thursday (see this post. I attempted a bit of live coverage on mastodon: day 1 and day 2. But it seems the semantic web community interested in SWAT4HCLS has not found the fediverse yet. So, make sure to check this full list of abstracts. -
Using compact identifiers in project reports
This document describes how you can improve the FAIR-ness of your project report by using compact identifiers. Of course, it can be applied to any other document too, and has been used in, for example, journal articles and online documentation already. -
SWAT4HCLS 2026 Amsterdam this week
Tomorrow, SWAT4HCLS 2026 will start, again in Amsterdam. The first SWAT4LS I attended was also in Amsterdam, and the second meeting in Amsterdam I was also there. And I was in Cambridge (see this post), Antwerp (no post), and at least to one of the two Leiden meetings (also no posts, it seems). -
CDK 2.12
Version 2.12 of the Chemistry Development Kit has been released. It is the last release with contributions by our NWO Open Science grant. This release adds some nice new APIs: -
Rescuing Scholia #3: We did it!
It was not a set up, when I openly wondered if we would be able to rescue Scholia in time. I honestly did not know. Three weeks and some serious hacking by an international team later I was more optimistic. Actually, just before christmas, we started writing a SWAT4HCLS 2026 demonstration abstract. This was accepted and you can read the Scholia 2026: Compliance with SPARQL 1.1 preprint here and here. This paper describes the work that had to be done, and I am deeply grateful to everyone who contributed with smaller or bigger contributions (Daniel, Peter, Konrad, Johannes, Lars, Wolfgang, Hannah). I am merely first author for the demo, and just another contributor to the long series of patches, in a branch started by Prof. Hannah Bast. -
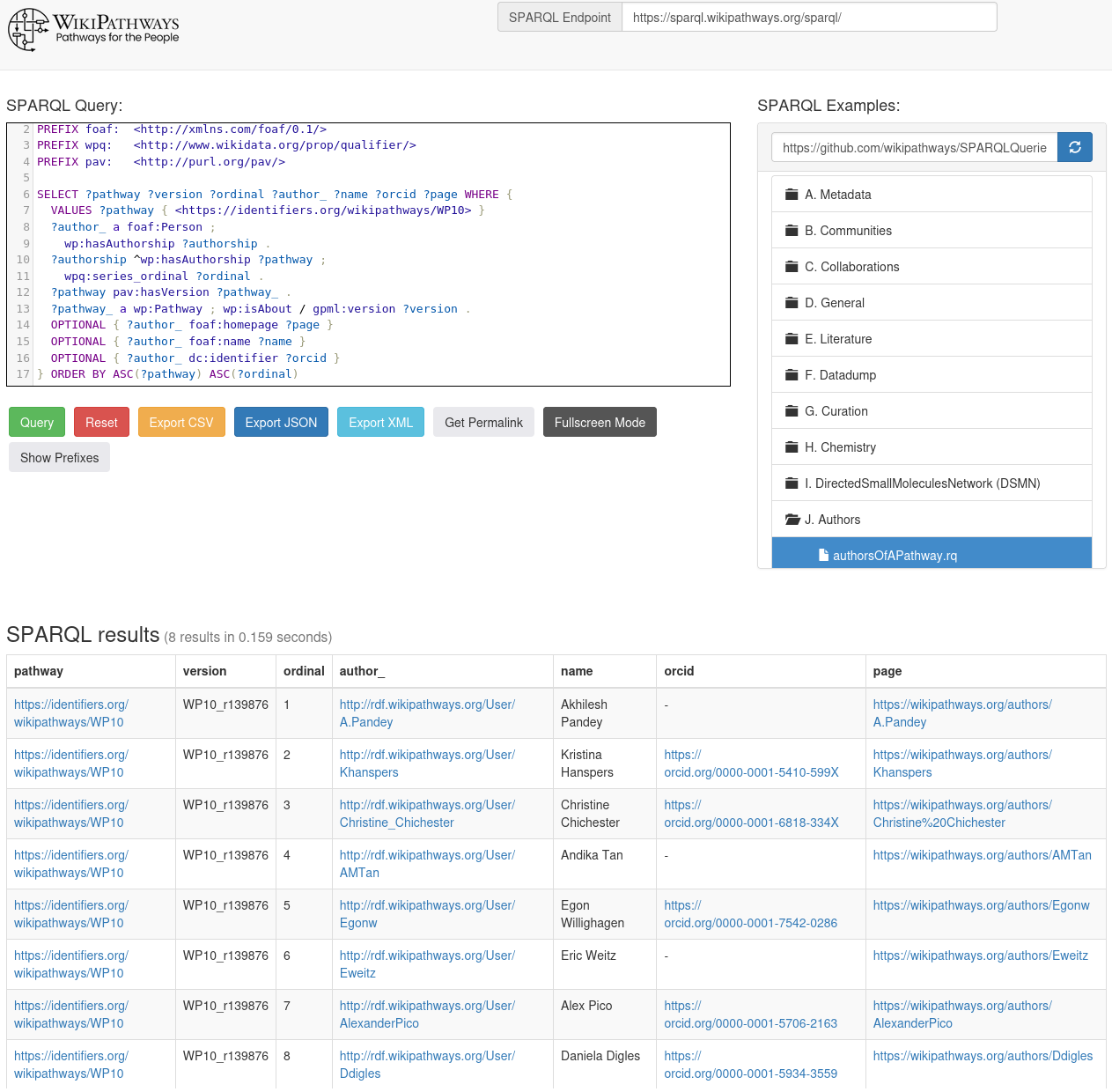
Where do the WikiPathways come from?
WikiPathways was founded in 2008, in the year I left Wageningen (and we Nijmegen) and moved to Uppsala, Sweden. When we dediced to move back to The Netherlands in 2012, I got to opportunity to join the Department of Bioinformatics (BiGCaT) and work on Open PHACTS. I had visited the group in March 2011 because I had a COST action workshop near Maastricht (about nanoQSAR) and the bioinformatics group did WikiPathways. -
The TDCC NES Col-Lab Retreat
Last autumn two TDCC projects started, FAIR4ChemNL (with the PeerTube channel and doi:10.61686/XVYQV45374) and FAIRify for metabolomics data (doi:10.61686/CSGIP04334). But I haven’t written much on either yet and what the role is our research group in these projects.