-
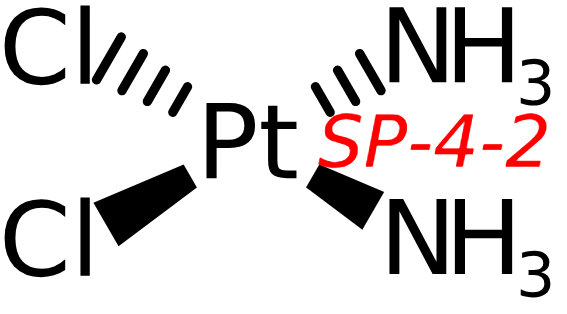
Molecular Inorganics: SMILES, MDL molfile v3000, and InChIs
Making chemistry more FAIR requires unique identifiers for chemical structures. For organic compounds plenty of solutions exist that do a great job. Last year and last week, I attended two technical InChI meetings, both with organometallic compounds and other molecular inorganics as one of the key topics. Thanks to Sonja (Mastodon bridge) and Gerd for the invitations. My role includes thinking about what all the work on the InChI means for the Chemistry Development Kit. -
Carbon beats gold: Diamond Open Access is the future #2
We need a lot more than diamond open access to really improve the publishing models. That said, but there are examples that diamond open access publishers actually want to improve more just the access to the knowledge dissemination infrastructure. But infrastructure is not only technologies; it also includes the many social aspects that are involved in adoption. And we saw enough of that in the open access transition. -
Carbon beats gold: Diamond Open Access is the future #1
Thirty years ago, researchers were struggling getting access to literature they wanted to read. I remember PhD candidates visiting friends at nearby universities for a meetup, and while there, for the copying machine in the remote library. Faster and cheaper than inter-library loaning. Scholarly journals were still printed on paper and distributed to university libraries. That was expensive. Therefore, many libraries provided only access to a subset of journals. -
Schema-Driven Interoperability of Biomedical Data Resources for Improved Knowledge Dissemination and Reuse (SchemaInterop)
Today starts a new project. NWO’s Open Science NL awarded Dr Tooba Abbassi-Daloii (Amsterdam UMC) with a grant to work on the interoperability between biomedical databases which all have different scope and design (doi:10.61686/AQNSM35060)). This project will create an open, interoperable framework to connect these databases, enabling efficient access and data use. By applying schema harmonization, aligning database designs, and using open science approaches, it promotes data transparency, reusability, and interoperability. Our approach implements the FAIR principles, ensuring analysis across databases is accurate and transparent, e.g., when combining gene expression data with gene variant knowledge. The project brings together researchers from the Amsterdam UMC, Universiteit Maastricht, and Leiden University Medical Center. -

The launch of the Virtual Human Platform
Nine days ago, the VHP4Safety project (see these posts) held a launch event in Utrecht for the Virtual Human Platform (VHP), a key result of the Dutch Research Agenda (NWA, from the Dutch Nationale Wetenschapsagenda). Despite the name, the NWA is just one part of the NWO funding mechanisms, but like the NWO Open Science programme it is funding with a specific purpose. And the purpose of the NWA is to answer research and societal questions that the Dutch people together defined and a public consultation (many years ago). VHP4Safety is answering to one of those questions. -
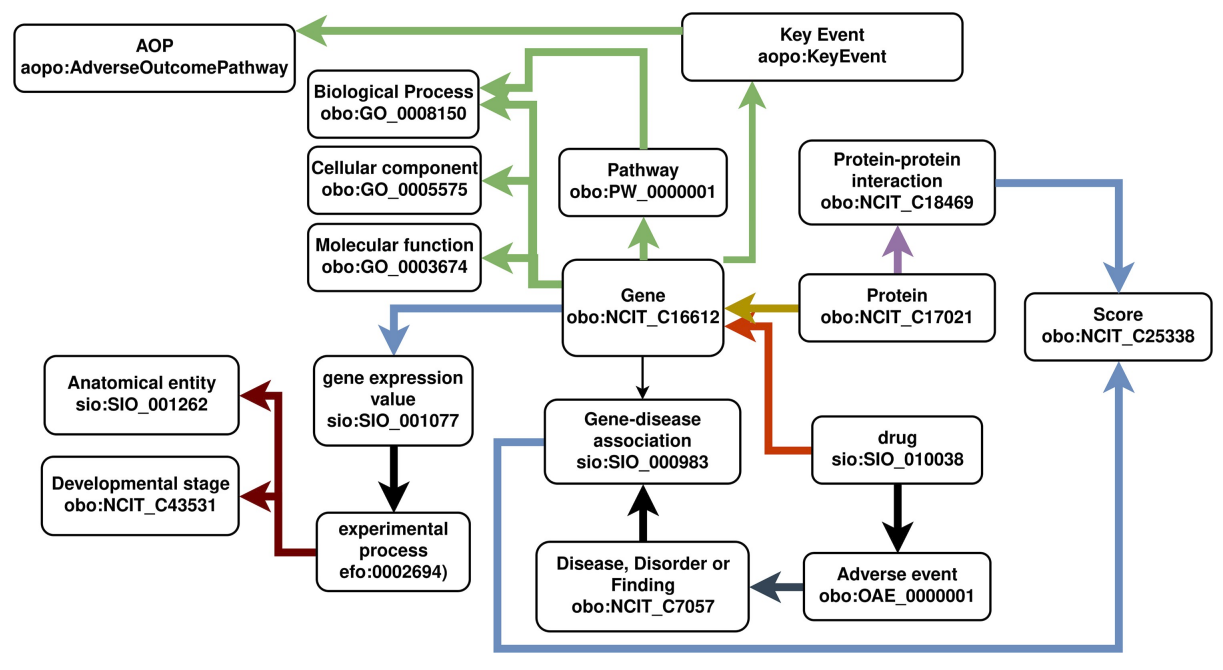
New paper: pyBiodatafuse: Extending interoperability of data using modular queries across biomedical resources
The number of data and knowledge source relevant to your biological or chemical question increases every year. They all come with different API and different data models. These need to be documented and mapped. What better way to do that than actually do that and then use that. I never asked, but I can imagine that was the original idea of Tooba and Yojana. At the very least, it demonstrates the level of interoperability we need in the life sciences. -
FAIR Implementation Profiles: Chemistry
I have had this on my todo list for way too long: writing about FAIR Implementation Profiles, or FIPs for short (see also doi:10.1007/978-3-030-65847-2_13):
- •
- 1
- 2