-
CiTO updates #2: annotation migration to Wikidata and first Scholia patch
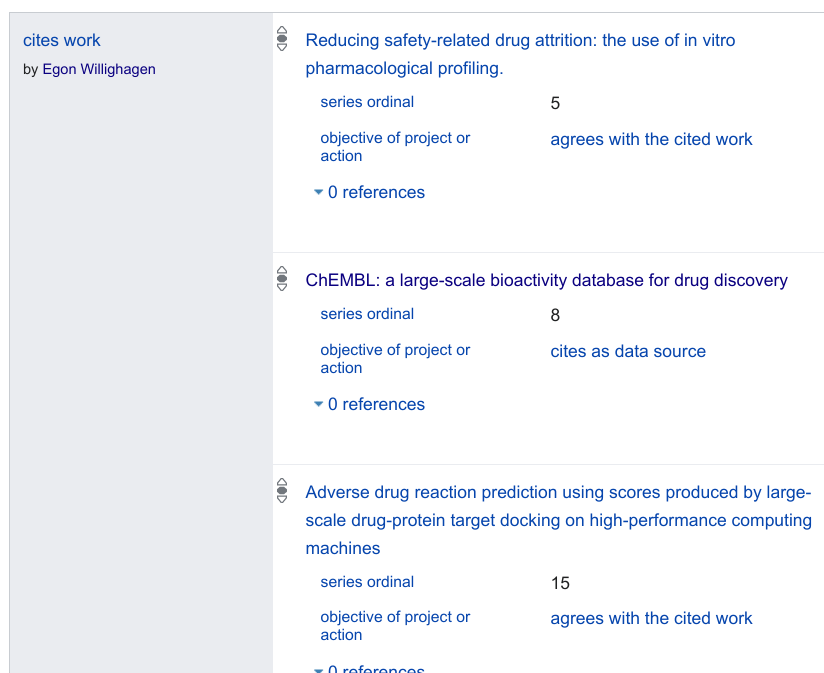
During the time of the editorial about the Journal of Cheminformatics Citation Typing Ontology (CiTO) Pilot I already worked out a model to add CiTO annotation in Wikidata. It looks like this for the first research article with annotation : -

CiTO updates #1: first research paper in the Journal of Cheminformatics with CiTO annotation published
After a time of exploration of technical needs, idea, plans, the Journal of Cheminformatics launched its Citation Typing Ontology (CiTO) Pilot this summer (doi:10.1186/s13321-020-00448-1). I am very excited about this, because the CiTO tells us why we are citing literature. We are a very long way away from publishing industry adoption, but we have to start somewhere. Laeeq Ahmed et al. published a few weeks ago the first research article with CiTO annotation of references (“Predicting target profiles with confidence as a service using docking scores”)! -
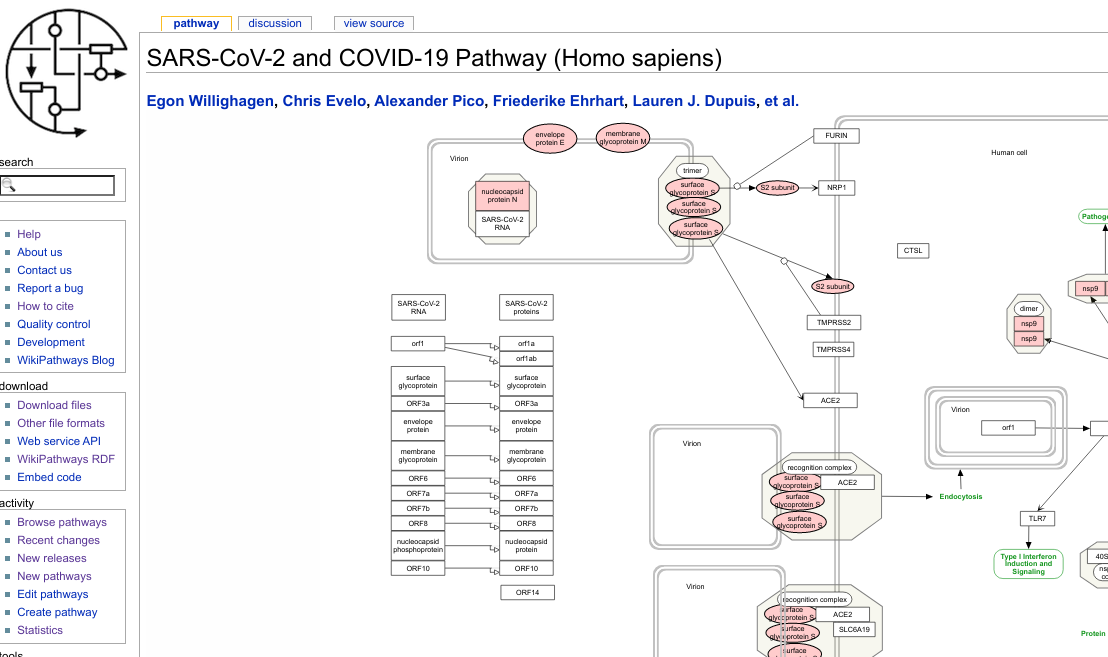
SARS-CoV-2, COVID-19, and Open Science
WP4846 that I started on March 16. It will see a massive overhaul in the next weeks. Voices are getting stronger over how important Open Science is. Insiders have known the advantages for decades. We also know the issues in the transition, but the transition has been steady. Contributing to Open Science is simple: there are plenty of project where you can contribute without jeopardizing your own research (funding or prestige). Myself, my small contributions have been done without funding too. But I needed to do something. I have been mostly self-quarantined since March 6, with only very few exception. And I’m so done with it. Like so many other people. It won’t stop me wearing masks when I go shopping (etc). -
Bioclipse git experiences #2: Create patches for individual plugins/features
This is a series of two posts repeating some content I wrote up back in the Bioclipse days (see also this Scholia page). They both deal with something we were facing: restructuring of version control repositories, while actually keeping the history. For example, you may want to copy or move code from one repository to another. A second use case can be a file that must be removed (there are valid reasons for that). Because these posts are based on Bioclipse work, there will be some specific terminology, but the approach I regularly apply in other situations. -
Bioclipse git experiences #1: Strip away unwanted plugins
This is a series of two posts repeating some content I wrote up back in the Bioclipse days (see also this Scholia page). They both deal with something we were facing: restructuring of version control repositories, while actually keeping the history. For example, you may want to copy or move code from one repository to another. A second use case can be a file that must be removed (there are valid reasons for that). Because these posts are based on Bioclipse work, there will be some specific terminology, but the approach I regularly apply in other situations. -
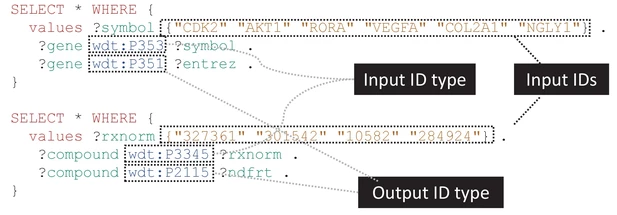
new paper: "Wikidata as a knowledge graph for the life sciences"
A figure from the article, outlining the idea of using SPARQL queries to extract data from the open knowledge base. As a reader of my blog, you know I have been doing quite some research where Wikidata has some role. I am preparing a paper on the work I have done around chemicals in Wikidata, based on what I presented at the ICCS with a poster. So, I was delighted when Andra and Andrew asked me to contribute to a paper outline the importance of Wikidata to the life sciences. The paper was published in eLife, which I’m excited about to, as they do a significant amount of publishing innovation.