-
The April 2025 Scholia hackathon
This is the third weekend I am working on Scholia, the first two part of the April 2025 hackathon. It follows the hackathons last year October and November hackathons. There is some urgency for this unpaid work, because Wikidata is splitting the RDF into two SPARQL endpoints (see this The Signpost and this post by Finn). This split has happened, but there is a legacy server for tools that have not been upgraded. -
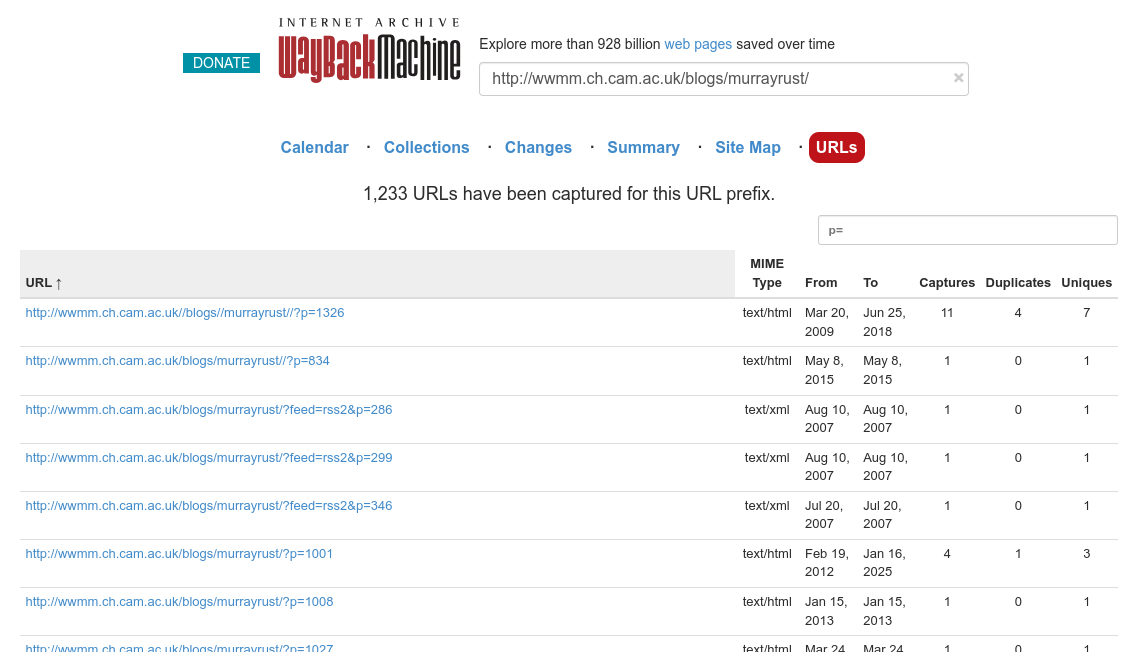
Updating links to blogs: Peter Murray-Rust
One reason to move my blog from Blogger to a git-backed repository is that I can update links but that the version history shows exactly what change was made. I have been using three icons: when I can find a new URL for the website, I use ; when I cannot find a new URL, but the old URL is in the Internet Archive, I use a ; finally, if I cannot find anything to replace the broken link, I use . For example, the blog of Rich Apodaca is now archived, and I have been updating the many links to his (still running) blog to use DOI links. That has the added benefit of making blog-to-blog citations more FAIR. -
cdk2024 #6: wrapping up already
Tomorrow is already the last day of the NWO Open Science grant for the Chemistry Development Kit. We are wrapping up, but I am happy we have a few weeks more to finish up the reporting. We held a user group meeting earlier this month (btw, check out the slides by Jonas), and I did a few more JUnit testing updates last week: -

New preprint: "BioHackEU24 report: ORCID and ROR identifiers in BioHackrXiv reports"
While this was not the primary hack project during the ELIXIR BioHackathon Europe last autumn, but I really like BioHackrXiv and I got the question if I could have a look at getting the ORCID logo in generated PDF. The ORCID was already in the YAML metadata of report markdown, so it sounded easy. Well, it was a big more complicated, but all the nicer to now have the project report online (doi:10.37044/osf.io/p9u42_v1). And once the ORCID was working, adding the Research Organisation Registry ID was not much harder. Cool to see both used in other recent BioHackrXiv reports! -
cdk2024 #5: Chemistry Development Kit User Group Meeting - Day 2
Where the first workshop day had several talks about new and old features of the Chemistry Development Kit (CDK), the second day was a hackathon day. We hacked and we talked. The coding was not mostly only the CDK repository itself, but some things happened there too: -
cdk2024 #4: Chemistry Development Kit User Group Meeting - Day 1
As part of our Dutch Research Council (NWO) Open Science grant, we organized a Chemistry Development Kit User Group Meeting (#CDK25UGM), of which yesterday was the “conference” day, and today a hackathon. -

One Million IUPAC names
Names of chemicals are part of the human user experience when browsing a chemical database. And literature too, of course. Chemical names are also not easy to use, and what a chemical name means is not always clear. This is why the IUPAC started a standardizing nomenclature in chemistry, the IUPAC names. Each IUPAC name uniquely defines the chemical structure it defines. For example, methane is the IUPAC name for the chemical CH4.