-
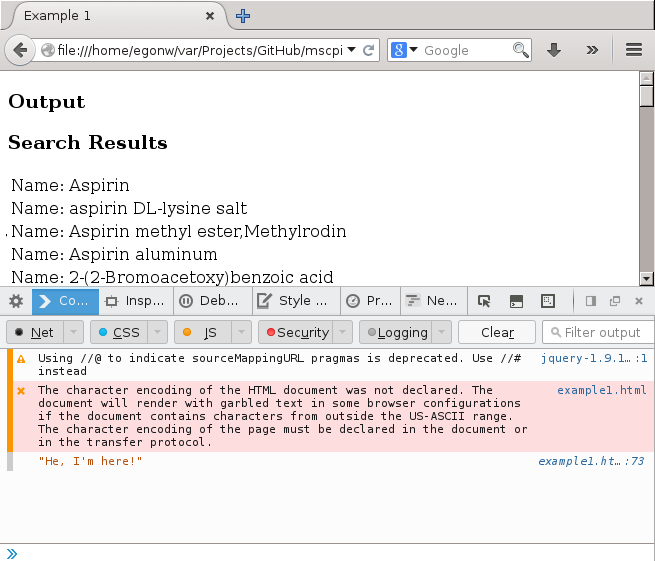
Programming in the Life Sciences #19: debugging
Debugging is the process find removing a fault in your code (the etymology goes further back than the moth story, I learned today). Being able to debug is an essential programming skill, and being able to program flawlessly is not enough; the bug can be outside your own code. (… there is much that can be written up about module interactions, APIs, documentation, etc, that lead to malfunctioning code …) -
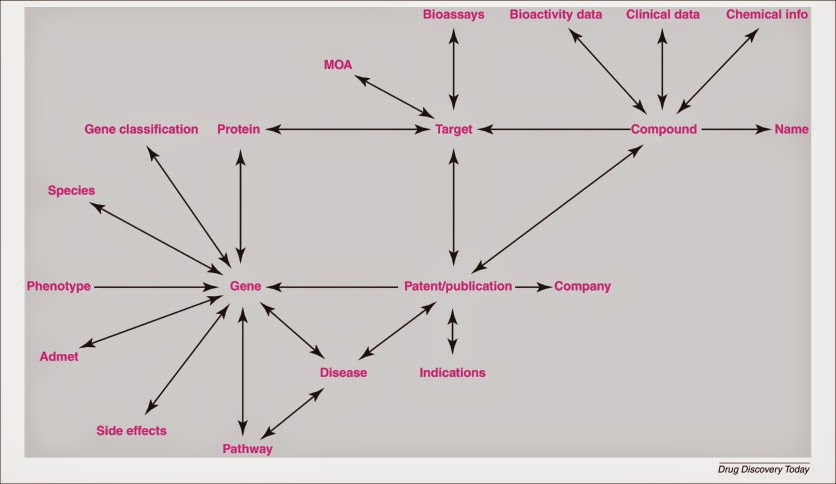
Programming in the Life Sciences #17: The Open PHACTS scientific questions
I think the authors of the Open PHACTS proposal made a right choice in defining a small set of questions that the solution to be developed could be tested against. The questions being specific, it is much easier to understand the needs. In fact, I suspect it may even be a very useful form of requirement analysis, and makes it hard to keep using vague terms. -

On Open Access in The Netherlands
Yesterday, I received a letter from the Association of Universities The Netherlands (VSNU, @deVSNU) about Open Access. The Netherlands is for research a very interesting country: it’s small, meaning we have few resources to establish and maintain high profile centers, we also believe strong education benefits from distribution, so we we have many good universities, rather than a few excelling universities. Mind you, this clouds that we absolutely do have excelling research institutes and research groups; they just are not concentrated in one university. -
Jean-Claude Bradley, Blue Obelisk award winner
Chemistry in Second Life. DOI:10.1186/1752-153X-3-14 There are nowadays a lot of people talking about Open, about open access, open data, open source. In fact, some discussion on Twitter resulted in the realization that it is highly unlikely that any scholar has not taken advantage of Open in some way in their research in the last few years. However, this is mostly due to people whom actually do, not by those who talk about it or use it. -
Slow publishing innovation: SMILES in ACS journals
Elsevier is not the only publisher with a large innovation inertia. In fact, I think many large organizations do, particularly if there are too many interdependencies, causing too long lines. Greg Laundrum made me aware that one American Chemical Society journal is now going to encourage (not require) machine readable forms of chemical structures to be included in their flagship. The reasoning by Gilson et al. is balanced. It is also 15 years too late. This question was relevant at the end of the last century. The technologies were already more advanced than what will now be adopted. 15 years!!! Seriously, that’s close to the time it takes to bring a new drug on the market! -
Elsevier's new text mining initiative is a step sideways
Elsevier’s new ideas on text mining are getting a lot attention now. Sadly, they get it wrong, again. On the bright side, all other publishers, which are expected to follow this year, can learn from this mistake. -
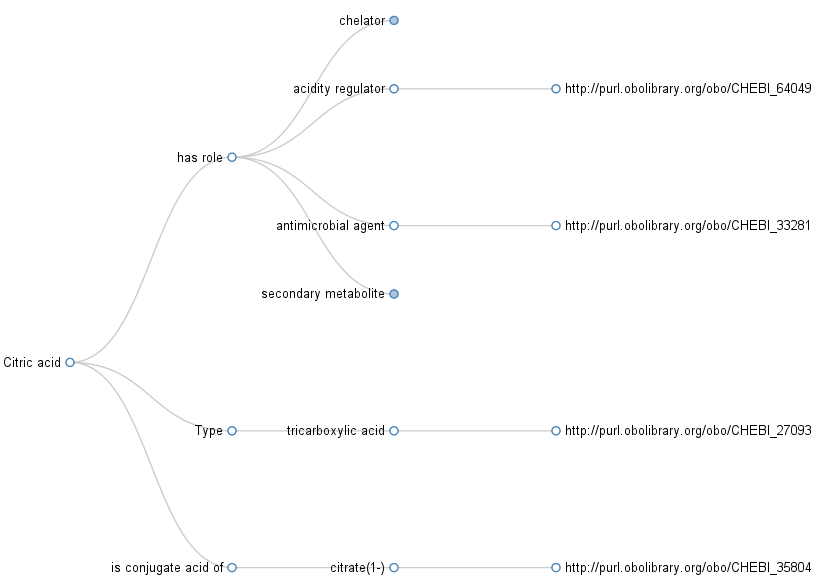
Programming in the Life Sciences #13: Another screenshot
I got a one more source code zip file from the Maastricht Science Programme students (see also the first two screenshots). Vincent and Błażej extended the d3.js tree view, showing classification information from ChEBI (they also submitted three patches to the Open PHACTS ops.js):