New paper: pyBiodatafuse: Extending interoperability of data using modular queries across biomedical resources
The number of data and knowledge source relevant to your biological or chemical question increases every year. They all come with different API and different data models. These need to be documented and mapped. What better way to do that than actually do that and then use that. I never asked, but I can imagine that was the original idea of Tooba and Yojana. At the very least, it demonstrates the level of interoperability we need in the life sciences.
In a recent paper, Yojana Gadiya, Javier Millán Acosta, and Tooba Abbassi-Daloii led a project called BioDataFuse (worked on at the biohackathons of ELIXIR in 2023 and 2024 and of SWAT4HCLS in 2024 and 2025) and the matching Python package, pyBiodatafuse (doi:10.1093/bioinformatics/btag064).
With a group of researchers from The Netherlands, Switzerland, Czech Republic, and the USA, multiple databases are wrapped in a uniform data model. The package allows the generation of a graph across the imported databases which can then be further analyzed and visualized. This is an example (RDF) graph that was generated:
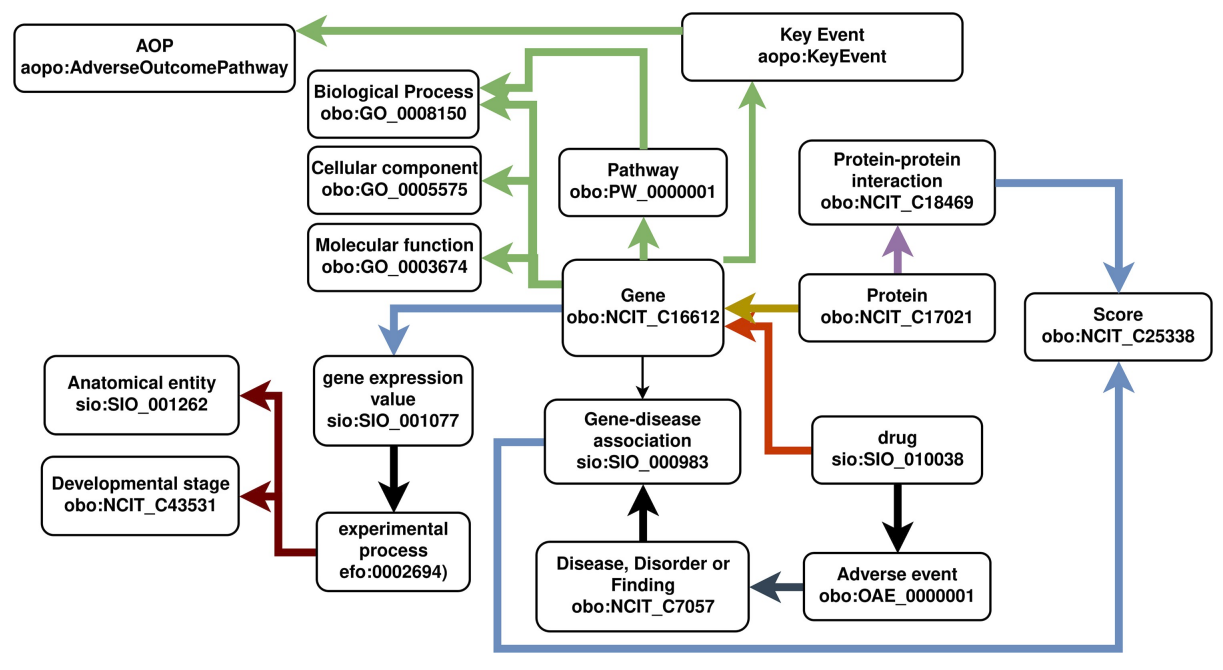
Seeing this kind of interoperability brings back good memories.
Congrats to all authors!
You can use your Mastodon or other ActivityPub-based Fediverse-account to comment on this article by leaving a publicly visible reply to this associated post. Content warnings are supported. You can also delete your comments at any time by deleting your post on the Fediverse.