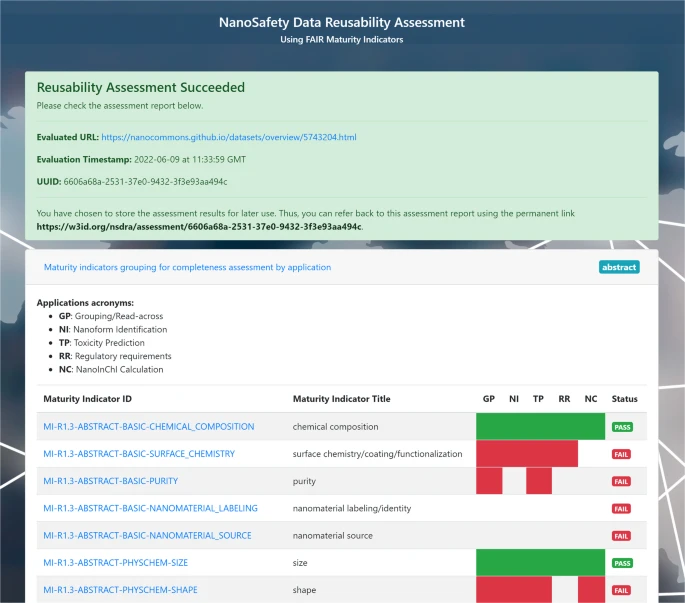
In this paper (doi:10.1038/s41597-024-03324-x), Ammar explores this notion and compiled more than 200 maturity indicators in the category R1.3 resulting from 12 different community standards. For example, this includes minimal reporting standards. There is overlap in needs, but they often also have a different focus. The conclusion here: different (re)use cases have different needs, and data not usable to one use case can be sufficiently FAIR for another. Of course, ideally, it would be FAIR enough for all use cases.
Ammar formalizes the maturity indicators and links the comming maturity indicators to various use cases. That means that when you determine the indicator values for your data, people can immediately lookup how this data can be reused. And, the generator of the data can immediately see how the data would need to be improved to widen the reusability. How FAIR can we get?
His proposal has already been further explored in two other papers, one around data sharing (doi:10.1038/s41596-024-00993-1, see also this blog post) and one around QSAR modelling (doi:10.1016/j.impact.2023.100475, see also this blog post).
The below screenshot shows what an analysis using this approach can look like: