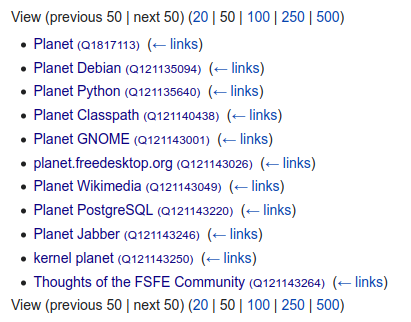
It turned out that planets do still exist, so I started a small corner on Wikidata: Q121134938, and a number of existing blog planets:
The software used to run these planets is ancient, though. We need a new generation of software, replacing things like Planet. And I want something people can easily host on GitHub or GitLab Pages or the likes.
I created a minimal shape expression but the Wikidata items for the planets still lack a lot of information that can be added. First, we can think of them as venues, perhaps, where people “publish” their work. Second, we can annotate the blog planets with ‘main subject’ for the topics the cover. Or we can list the people that are “author” on the planet; most planets are very transparent about which blogs they aggregate.
Love to see where this is going. Who knows? Maybe we will see Postgenomic (see doi:10.1186/1471-2105-8-487) and Chemical blogspace resurface :)
]]>