One of the things, is that the CiTO data added via a certain account, can be downloaded as triples:
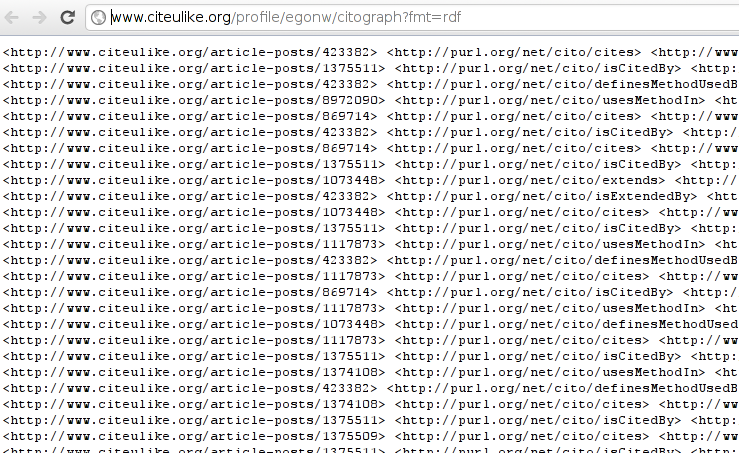
The second is that they are improving the graphics of how it is visualized. E.g. they added an ‘Expand’ link, which I found when they tweeted they had hidden drag-n-drop, which I haven’t found yet, though. Clicking that action, will show you the following:

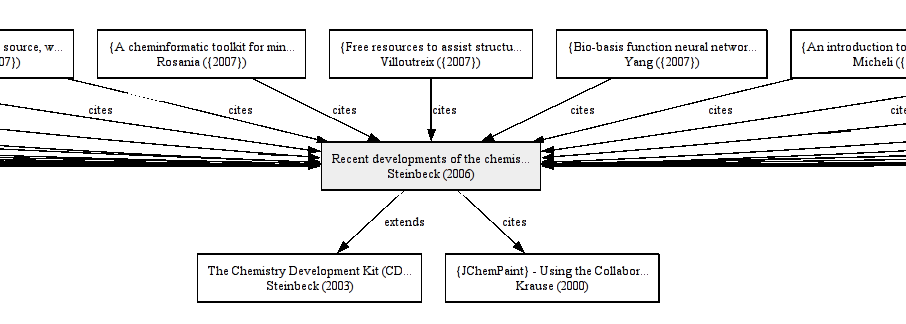
Because CiteULike takes advantage of the inverse function of the CiTO predictates, they show up with the cited paper too, which is less suitable for the top-down flow graphics:
To make this advertorial a bit balanced, not all my wishes have been implemented yet, and the next up from my perspective should be Linked Data. There is some Linked Data embedded as RDFa, but the latter is not turning out to be the killer I had hoped, and regular RDF entry points should be used.
Each CiteULike entry (post) should get a unique IRI (or URI) and opening that link should give RDF about that post (wish #10). That’s is dereferencibility. The RDF can be, for example, in BIBO but there are many alternatives, and I have not been keeping up with which is the best (please leave a comment, if you have an opinion on that).
But I like where this is going! Thanx, CiteIReallyLikeThis!
]]>